Pour rentrer dans le vif du sujet, voici les modifications apportées sur l’export RDF de pearltrees :
Fixe des problèmes de casse
Remplace owl:sameAs par dc:identifier sur la class pt:Pearl
Remplace owl:sameAs par rdfs:seeAlso sur les perles référencant des pt:Tree
Remplace le préfix dc: par dcterms:
Utilisation de sioc:UserAccount pour lier foaf et pearltrees
Description simple du schéma pearltrees sur l’url associé
Ajout de pt:inTreeSinceDate sur pt:Pearl
Ajout de pt:treeId, pt:assoId et pt:lastUpdate sur pt:Tree
Sur l’année passée j’ai reçu avec grand plaisir les retours de nombreuses personnes, je tiens à remercier particulièrement Alexandre, Gautier et Vincent pour leurs feedbacks détaillés. Ces derniers mois l’export RDF était bien loin de mes préoccupations. Et pour quelque temps encore le produit coeur de pearltrees va être pour moi source de toute mon attention. Ceci dit, j’ai décidé d’avoir une démarche plus active sur cet export RDF. A la fois format d’avenir et particulièrement liée à la nature de pearltrees, je suis ouvert à une intégration de vos remarques dans le cycle des itérations de pearltrees. Vous avez une idée pour améliorer cet export ? Soumettez moi vos idées, elles seront intégrées dans l’itération courante.
Je vous invite à créer un compte pearltrees, et explorer par vous même votre export. Sinon vous pouvez toujours jouer avec mes données (2,2Mo) dont 2800 perles, non, ce n’est pas sale 🙂
Un petit exemple d’utilisation de l’export et de l’interface javascript de l’embed:
En cliquant sur les liens suivants vous pouvez piloter l’embed ci-dessus 😮
Je remplaçais « édition » par « curation » et j’obtenais le titre le plus buzzy du moment 🙂 En réalité, je voulais souligner que ces deux tendances sont bien plus liées qu’on pourrait le penser. Alors pourquoi a-t-on tendance à opposer web sémantique et édition humaine (human curation) ? La raison est plutôt simple :
derrière le web sémantique on associe les robots et les ontologies
derrière l’édition humaine on associe les gens et la subjectivité
Bien évidemment cette opposition est bien rapide puisqu’elle fait l’hypothèse que les sources de données sont générées entièrement par des algorithmes. En réalité le web sémantique se nourrit de contenus édités humainement et les données liées s’enrichissent par des éditions externes. Prenons l’exemple du site de musique de la BBC, les pages d’artistes comme celle ci sont générées à partir de différentes sources de données. Or ces sources de données sont dans la plus part des cas éditées humainement : DBPedia (wikipedia) et MusicBrainz ne sont ils pas des exemples incroyables d’éditions humaines ?
Aujourd’hui les éditeurs de données musicales ou de données encyclopédiques ont leur communauté et leur plateforme. Les éditeurs du web ont également la leur. Des sites comme la BBC l’ont bien compris et plutôt que de construire leur propre base de données, la BBC non seulement utilise des sources externes mais surtout participe à l’édition de ces sources. Quand un journaliste de la BBC découvre un nouvel artiste, que fait-il ? Il va éditer wikipedia et MusicBrainz. L’erreur est de penser que le web sémantique se caractérise par l’échange de données éditées par des communautés distinctes. En réalité à partir du moment où vous associez les données de deux services d’édition de contenus, vous associer également les éditeurs. Web sémantique : moyen de transport pour les éditions humaines ?
Que cela soit sur le blogue de Georgi Kobilarov ou dans le dernier numéro du magazine Nodalities, je suis très heureux de voir la notion de « human curation » apparaitre dans les discussions. Ce point est important car il ne s’agit pas de reasoning automatique, il s’agit bien de la place des communautés dans le cycle de vie et la transformation des données.
Que cela soit sur ce blogue ou sur participation@pearltrees.com, vous avez été nombreux à vouloir en savoir un peu plus sur les technologies utilisées pour fabriquer toutes ces perles. Le web, internet et l’informatique en générale étant une succession de technologies empilées les unes sur les autres, je vais essayer de lister quelques technos essentielles ainsi que représenter de manière simplifiée notre architecture de production.
Interface utilisateur
Flex
Flex est un Framework ActionScript (Flash) qui nous permet de développer l’interface utilisateur de la version web. Il nous a permit de développer très rapidement une interface riche et de la déployer sur un très grand nombre de terminaux. Aujourd’hui notre challenge principal est la maitrise de la taille de l’application générée.
HTML
Utilisé principalement pour nourrir les moteurs de recherche et proposer une version alternative aux terminaux ne supportant pas flash. L’ensemble du contenu de pearltrees est disponible au format HTML. Nous avons également beaucoup travaillé sur HTML lors du développement de l’embed pearltrees, avec des problématiques d’intégration dans des milieux non maitrisés, voir même hostile 🙂 Nous y utilisons des propriétés HTML5.
Javascript
Nous utilisons javascript dans un très grand nombre de cas, animations du browser pearltrees, embed, addons… Nous utilisons JQuery pour les manipulations du DOM.
RDF
Le RDF est un format du web sémantique que nous utilisons pour l’export des données de pearltrees. Plutôt que de créer encore un schéma XML de plus, RDF est un format plus adapté pour le partage de données liées. Et nos perles sont à la fois liées entre elles et liées à des URLs.
C++
L’addon IE est entièrement développé en C++. Ayant des addons sur Firefox, Chrome et Safari, IE est très clairement la plateforme la plus pénible pour y développer des addons.
Objective-C
Objective-C, pour ce que vous imaginez, mais je ne peux pas en dire plus 😉
Côté serveur
Java
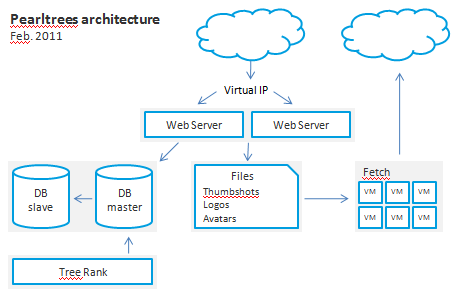
Nous utilisons Java 6 et Tomcat pour faire tourner l’application pearltrees (nom de code : « oyster »), ainsi que notre algorithme de proximité: « Tree Rank ». Grâce à sa « secret sauce » Tree Rank nous permet de calculer la proximité des pearltrees les uns par rapport aux autres et de faciliter la découverte de contenus proches. Historiquement en PHP, depuis septembre 2009 Java est aujourd’hui utilisé dans la majorité de nos programmes serveurs. Nous utilisons Lucene comme base de notre moteur de recherche.
PHP
Notre backend utilise toujours PHP. Historiquement sur Zend Framework et Apache, la majeure partie du code serveur est maintenant en Java. Nous avions des problèmes de performance avec le framework Zend et en même temps de l’expertise en Java, le choix de migrer c’est vite imposé. Ceci-dit nous avons encore des applications en Zend Framework puisque que nous utilisons Piwik comme outil de stats.
MySQL
Comme base de données principale, nous utilisons MySQL 5.1 sur 2 gros bébés (48Go Ram, 32 CPU) en réplication master-slave. La base contient 35 tables et plus de 60 millions de lignes.
NFS
Notre serveur de fichier utilise NFS v3 pour partager logos, avatars et thumbshots. Notre serveur NFS est loin d’être configuré de manière optimale et il est souvent source de lenteur dans la livraison de nos fichiers. Un passage sur une solution de cloud computing semble inévitable à moyen terme. Nos 160Go de fichiers sont également répliqués à travers le monde via CDN (level3).
Xen
Xen permet la virtualisation de notre programme « Fetch » qui tourne sur 16 machines virtuelles. Fetch gère entre autre la génération des thumbshots et la préparation du pré-chargement des pages lors de la navigation dans pearltrees. Nous sommes aujourd’hui capable de traiter 10.000 URLs / h. Nous sommes donc capables de reprocesser la totalité de notre base de thumbshots en 15 jours.
Bash, Python
L’administration des machines se fait principalement à l’aide de scripts. Ces derniers sont logiquement en bash et en python. Nous utilisons également python dans un programme permettant de detecter les URLs n’acceptant pas d’être vues dans une iFrame.
Backend
Bugzilla
Nous utilisons Bugzilla pour définir la priorité des bugs et suivre leur évolution. Aujourd’hui l’état de notre bugzilla est le suivant:
Subversion
Tout notre code est versionné et découpé en branches grâce à SVN. Nous en sommes aujourd’hui à plus de 23.000 commits !
Architecture de production
Ci-dessous la version simplifiée de l’archi actuelle. Nous avons également une architecture de pré-production semblable à l’archi de production et également une architecture de développement avec des mécanismes de déploiement vers la « prod » ou la « preprod ».