
Voila un sujet que j’ai peu traité depuis la création de ce blogue. Et pourtant quand on regarde ce qui compose le web d’aujourd’hui, la navigateur web en est une pièce indispensable dans son fonctionnement. Les autres grandes composantes du web étant les pages webs, leurs adresses, et le réseau pour y accéder. Je vous propose donc un article de prospective en plusieurs parties sur le futur du navigateur web et plus précisément comment le web des données va en changer la forme.
partie 1: nous ne navigons plus sur la même toile
Dans les premiers jours du web les pages et les données étaient plutôt copines puisqu’elles se confondaient. L’on développait directement des pages HTML, sans base de données. Très vite le divorce: les données sont enfermées dans des bases, et le rôle du HTML se retrouve limité à présenter ces données aux navigateurs webs. La valeur des sites web réside alors dans l’accumulation de données, soigneusement protégées et diffusées de manière très contrôlées, car bien souvent directement monétisées.
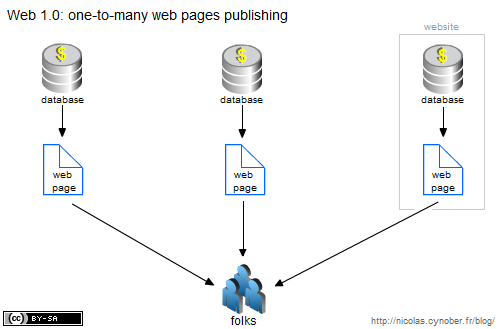
Arrivée du web 2.0: 1er effet kisscool. Des millions, puis des centaines de millions, puis un milliard d’utilisateur produisent des données. Le marché est plutôt simple: les sites web permettent l’échange de données entre les internautes et en contre partie les sites continuent de remplir leurs bases de données, augmentant ainsi leur valorisation. Finalement la relation entre données et pages webs reste quasiment inchangée, les utilisateurs créent des données pour un site, pour une base de données, et ces données sont ensuite affichées sur ce même site à travers ses pages webs.
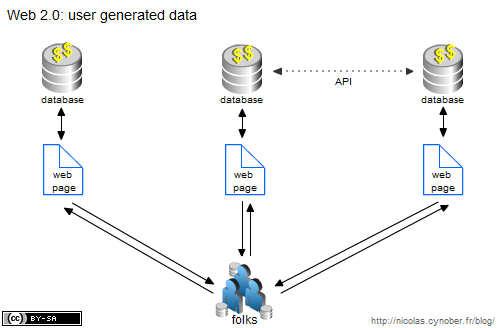
Arrivée du web 3.0: 2ème effet kisscool. Les sites webs se sont rendu compte que leurs données avaient beaucoup plus de valeurs quand elles étaient associées avec celles du voisin. Vous connaissez les mashups? C’est peanuts à côté de ce qui nous attend avec le LinkedData. L’interconnexion de ces bases de données, précieusement gardées depuis la création du web, pourraient bien créer quelques changements. A cela s’ajoute notre milliard d’utilisateurs qui revendiquent la propriété et le contrôle des données qu’ils produisent, et vous obtenez quelque chose comme ça:
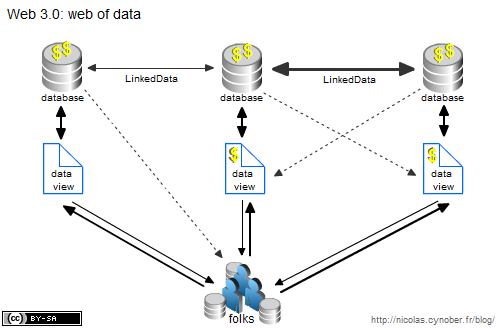
La constante: dans cet environnement les pages web permettent toujours de visualiser les données. Petit changement: elles permettront bientôt de visualiser des données provenant d’autres sites ou directement des internautes. La valeur des sites web ne réside plus uniquement dans leur base de données mais aussi dans leur capacité à enrichir leurs données et à les visualiser.
Mes sources pour la suite de l’article:

10 responses so far ↓